
在现代商业竞争中,快速高效反应已成为企业争夺客户的秘诀。随着全球化和互联网的普及,供需双方信息的透明化程度不断提高,企业能否高效快速地匹配客户需求并解决问题,成为决定其竞争力的关键因素。最近,我通过运用Python自动化办公技术,帮助朋友的公司迅速响应客户需求,取得了客户的信任和大订单。
事情是这样的,一个大客户由于品牌更改和领导层的变动,需要批量修改之前已经制作好的产品样册。这些样册以PDF格式提供而且数量巨大。为了尽早上市,这个客户给所有的合作供应商都发送了PDF产品册,也就意味着谁能第一时间完成修改,谁就能拿到这个大订单。
当对这些PDF图册直接进行修改时,问题就出现了。由于PDF文件本身的特性,直接编辑它们会遇到各种解析问题,使得修改过程变得困难且耗时。为了解决这个问题,公司美工提出将PDF文件转换为图片格式,再使用专业的图像编辑软件PS进行修改。但是客户给的产品册数量巨大,手动将每个PDF文件转换为图片格式是一项繁琐且耗时的任务,特别是在处理大量文件时。
面对这一挑战,我提出了一个解决方案:利用Python脚本将客户给的所有PDF文件批量转换为图片格式,再由美工使用专业的图像编辑软件进行修改。
python代码
pip install PyMuPDFimport fitz # PyMuPDF库,用于处理PDF文件 import os # from PIL import Image def pdf_to_images(pdf_folder, output_folder): # 遍历指定文件夹中的所有PDF文件 for pdf_file in os.listdir(pdf_folder): if pdf_file.lower().endswith(('.pdf', '.PDF')): pdf_path = os.path.join(pdf_folder, pdf_file) # 打开PDF文件 doc = fitz.open(pdf_path) # 创建输出文件夹(如果不存在) output_subfolder = os.path.join(output_folder, os.path.splitext(pdf_file)[0]) if not os.path.exists(output_subfolder): os.makedirs(output_subfolder) # 遍历PDF的每一页 for page_num in range(len(doc)): # 获取当前页的Pixmap对象 page = doc.load_page(page_num) image = page.get_pixmap() # pix = doc.get_page_pixmap(page_num, alpha=False) # 将Pixmap对象转换为PIL Image对象 # image = Image.frombytes( # "RGB", # [pix.width, pix.height], # pix.samples["RGB"], # "raw", # "RGB", # pix.stride, # -1 # ) # 保存图片到指定文件夹 output_path = os.path.join(output_subfolder, f"{pdf_file.replace('.pdf', '')}_page_{page_num+1}.png") image.save(output_path) # 关闭PDF文件 doc.close() # 示例使用 pdf_folder = "./" # PDF文件所在文件夹路径 output_folder = "product_images" # 输出文件夹路径 pdf_to_images(pdf_folder, output_folder)这个脚本将遍历指定文件夹中的所有PDF文件,并将每个文件的每一页转换为PNG图片。转换后的图片将保存在与原始PDF文件同名的子文件夹中,并以特定的命名规则进行命名。
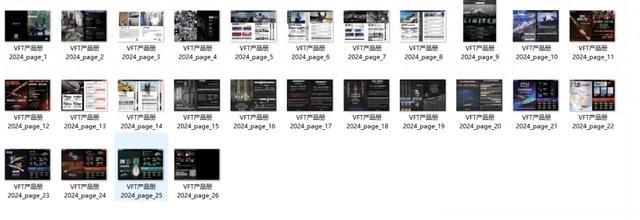
结语
通过Python自动化批量PDF转图片的操作,我成功帮助朋友的公司快速响应了客户需求,提升了客户满意度,成为第一个完成任务的公司成功拿下客户大订单,当其他合作商还在拼命地堆人力解决批量PDF转图片的问题时,我们已经将修改好的产品册发给客户了。这就是Python自动化办公技术的强大能力,掌握这一技能将使我们在未来的工作中更加高效、专业。
